The state of the art for crediting AI in git is one line: Co-authored-by: Copilot.
It doesn’t say which model, how many lines, or whether they survived, and it says nothing when three agents touched the same commit. As a basis for deciding what to pay for, it’s almost useless.
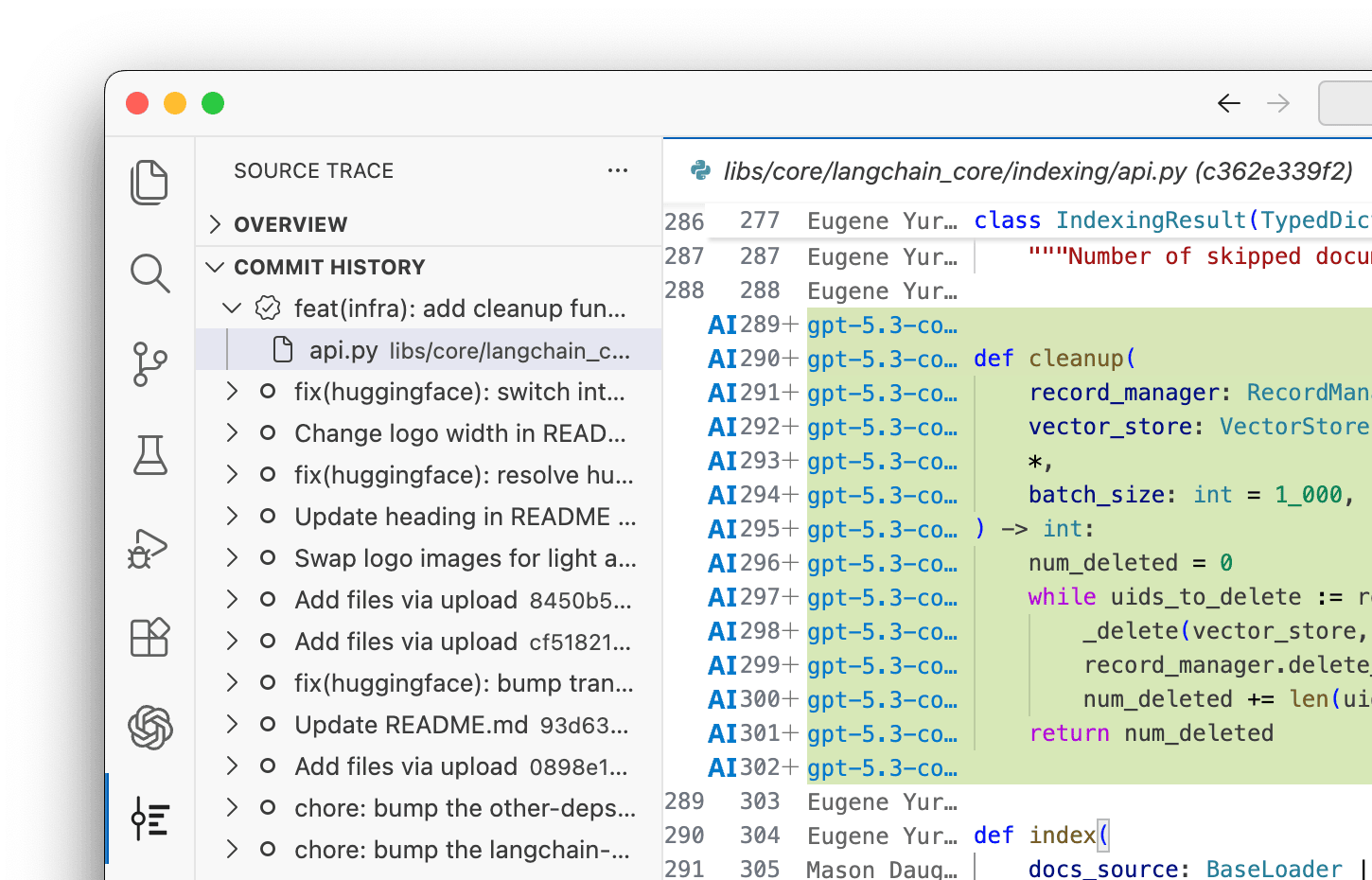
That matters as the bill grows. Teams now run several tools at once: a flagship agent for hard problems, a cheap one for boilerplate, an IDE assistant for completions, each billed in different units. The reasonable question is which of these is worth the money. Per-model survival data can answer it.
The calculation
Two agents each write 10,000 lines this month. Agent A survives at 80%, so 8,000 lines earn their keep. Agent B survives at 45%, so 5,500 lines are kept and the rest is churn your developers had to clean up. Same cost, very different contribution. Now the licensing decision rests on kept code instead of a feeling.
Do it honestly and you measure against a baseline. A 30% discard rate on AI code sounds alarming until you notice developers discard 28% of their hand-written code in the same repo. That’s just how code churns. So we report excess rework, which is the gap between the AI and human discard rates in percentage points. If that gap is a few points, the AI is deliering on par with engineers. If it’s twenty, the tool is slowing down your development, and that’s where you start asking questions.
This is the point where Source Trace went from an interesting personal metric to an input to a budget. When AI pricing is changing every month, we want teams to compare, and pick the best model. We are not affiliated with any model providers.